
minidump
这道题其实是实验室的会长安排的,我一开始也没反应过来。
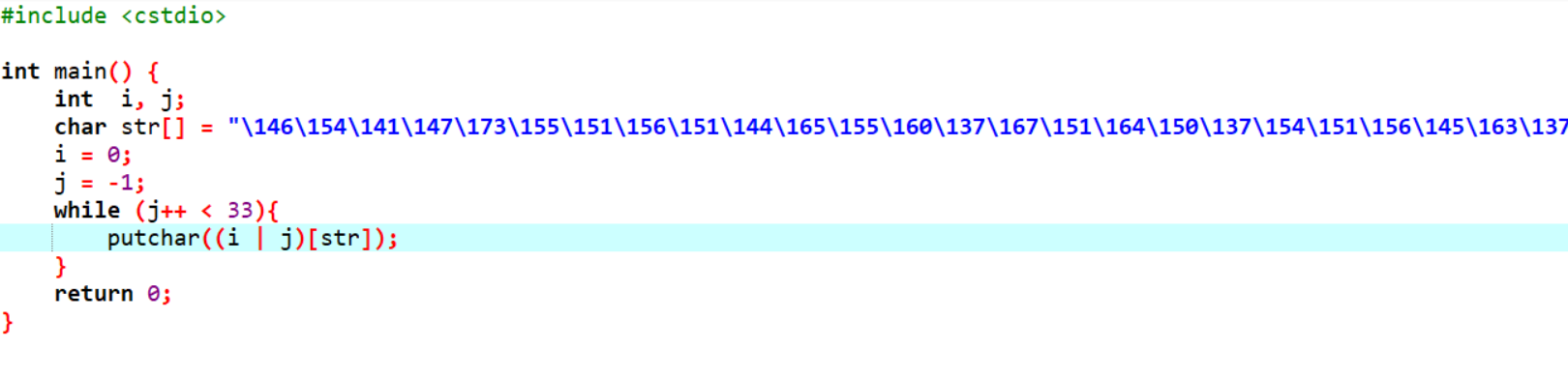
dmp文件其实是dbg或者系统错误时产生的内存转储,但是,我们不一定需要专业的软件来打开它,就比如这题,出题人摆明这是c++程序的内存转储,而整个程序的源代码其实在运行时写入了内存,以便后续处理,所以我们直接winhex或者010editor打开,搜索相关字样,比方说“#include”即可,就可以快速跳转到对应代码:

我们把代码扒出来,稍微小修小补一阵,看一看,就是个很简单的输出,运行,结束。
好像有点不对
其实,前半截加密就是base64,只不过我把密码表改成了各位没见过的样子(
后半段嘛……其实跟随机数的生成本身也没太大关系,既然不知道它生成的随机数值到底是什么,那么就粗暴一点,直接爆破。
那么,思路很清楚了,对结果串从0~89暴力爆破,产生的产物,能看的直接塞到cyberchef里,换个base64的表挨个试一遍(下面的代码用c++实现):
#include <bits/stdc++.h>
using namespace std;
const char data_0[] = {37,29,51,58,33,123,57,35,30,78,93,95,91,117,99,74,123,13,6,85,127,125,115,65,80,11,89,87,44,120,51,50,15,22,47,119};
int main()
{
freopen("output.txt","w",stdout);
for(int i=0;i<=114-24;i++){
bool jud = true;
char data_1[114];
strcpy(data_1,data_0);
for(int j=0;j<strlen(data_0);j++){
data_1[(j+i)%strlen(data_0)] ^= i+j;
}
puts(data_1);
}
return 0;
}


山外青山楼外楼
顾题思义,这题的flag藏在你的视野之外。
实现这题的技术来自于DEF CON 23,名叫REpsych,可以实现将位图贴到你的程序的控制流图,也就是所谓的ast语法树在ida中的表现上。我在Nepctf2022做到了相关的题目,相关github链接我也放在这,方便各位查阅。
那么知道这是位图了,我们怎么在ida里看呢?很简单,你需要进入ida的设置,调节一下流图显示的上限。打开options->general->graph,将Max number of nodes 调到一定大小即可,比方说114514(。
至于要看的更清楚的话,可以options->color->graph,把背景全部涂黑,这样,一张图片就显示出来了:

顺带,可能低版本ida的流图显示和高版本有一定差距,还请注意
看不见 ~ 走位 ~ 走位 ~
我摊牌了,这本来是一个经典的迷宫,但是我塞进去了一些隐形墙。
宋师傅几次与正解失之交臂,估计也是因为没能理解隐形墙的实现方式。
我们来对比一下隐形墙函数在ida中和在源代码中的表现:
_BYTE *func_0()
{
_BYTE *result; // rax
int i; // [rsp+Ch] [rbp-4h]
for ( i = 0; i <= 13; i += 2 )
{
result = &data_1[12 * data_4[i] + data_4[i + 1]];
*result = 42;
}
return result;
}
------------------------------------------------
int data_4[14] = {1,1,1,8,9,2,4,9,3,10,7,4,3,5};
int func_0()
{
for(int i=0;i<14;i+=2)
data_1[data_4[i]][data_4[i+1]]='*';
}
我故意将坐标数组合二为一,但如果能理解经典地图题的实现,就能发现,每一个i和i+1对应的就是地图上的纵横坐标。
此外,我还在func_2对输入数据做了一些预处理,使上下左右四个方向能直接对应上数组的下标:

那么,接下来就轮到解题了。老规矩,你可以把地图拷下来,再把隐形墙贴上去,然后,要么手动走一遍,要么用算法脚本:
#include <bits/stdc++.h>
using namespace std;
char mp[12][12] = {
'*','*','*','*','*','*','*','*','*','*','*','*',
'*','*','_','_','_','_','_','_','*','_','_','_',
'*','_','*','_','*','*','*','_','*','_','_','*',
'*','_','_','_','_','*','*','_','*','T','*','*',
'*','*','_','*','*','_','_','_','*','*','_','*',
'*','*','_','_','T','*','*','_','_','_','_','*',
'*','*','_','*','_','*','*','_','*','*','_','*',
'*','*','_','_','*','_','_','_','*','*','_','*',
'*','*','_','*','*','*','*','_','*','_','_','*',
'*','*','*','*','*','*','*','_','*','_','*','*',
'*','*','*','*','*','*','*','_','*','_','*','*',
'*','*','*','*','*','*','*','S','_','_','*','*'
};
int walked[12][12];
int mvy[4] = {-1,1,0,0};
int mvx[4] = {0,0,-1,1};
int path[114];
int shortest[114];
int total=0xff;
void dfs(int stp,int y,int x){
if(mp[y][x]=='T'){
if(stp<total){
total = stp;
for(int i=0;i<stp;i++)shortest[i]=path[i];
}
return;
}
for(int i=0;i<4;i++){
path[stp]=i;
if(y+mvy[i]<12&&x+mvx[i]<12&&y+mvy[i]>=0&&x+mvx[i]>=0&&mp[y+mvy[i]][x+mvx[i]]!='*'&&!walked[y+mvy[i]][x+mvx[i]]){
walked[y+mvy[i]][x+mvx[i]]=1;
dfs(stp+1,y+mvy[i],x+mvx[i]);
walked[y+mvy[i]][x+mvx[i]]=0;
}
path[stp]=0xff;
}
return;
}
int main()
{
memset(path,0xff,sizeof(path));
walked[11][7]=1;
dfs(0,11,7);
for(int i=0;i<total;i++){
if(shortest[i]==0)printf("u");
if(shortest[i]==1)printf("d");
if(shortest[i]==2)printf("l");
if(shortest[i]==3)printf("r");
}
printf("\n");
return 0;
}
各位如果有时间,掌握一些简单算法是必要的,在比赛时绝对有效。比如同样是曾经的nepctf就考了一道广度优先搜索,那是另一种类型的迷宫,各位有兴趣可以看看我以前的复现或者其他dalao的题解,在此不多赘述。
分块式处理
从10分的hint可以看出来,这是一道原题。
感兴趣的各位可以查看我曾经写过的文章,这道题是BMZCTF的逆向_RE2,各位研究出来了也可以去BMZCTF蹭点分,这里不再赘述。
彻底疯狂
如果你点进func_0或者是其它同系列函数稍微观察一下,你就会发现,它们的结构都非常相似:

都是对全局变量value进行异或,只是异或的值有点不同,函数的运行顺序从编号0到99。
为了方便把这些值提取出来,你需要在汇编代码里列出所有的异或语句:

这时候你就不用一个函数一个函数的点了,直接从这里手动把东西全扒下来。当然,如果要操作优雅一点,你可以按字节码和地址去用脚本拔下来这些东西,这里就不演示了。
如果将数据以十进制的方式提取出来,那它大概长这样:
920682
1261524
338231
563319
1167774
……
异或具有自反性,所以接下来只要让结果值对其中的数据按顺序异或就行了:
f = open("randata.txt", "r")
data_0 = f.read().splitlines()
data_1 = []
for line in data_0:
data_1.append(int(line))
print(data_1)
finale = 0xF8B3E
l = len(data_1)
for i in range(l):
finale ^= data_1[l - (i + 1)]
print("flag{"+str(finale)+"}")
顺带,这里是我用来出题的脚本,各位可以研究一下(一些库函数和main的内容我就懒得在这里fwrite了):
import random
f0 = open("randata.txt", "w")
for i in range(100):
f0.write(str(random.randint(114514, 1919810))+"\n")
f0.close()
fa = open("randata.txt", "r")
data_0 = fa.read().splitlines()
data_1 = []
for line in data_0:
data_1.append(int(line))
f1 = open("craaaaazy_encode.c", 'w')
for i in range(100):
f1.write("void func_" + str(100-(i+1)) + "(){\n")
f1.write(" value ^= " + str(data_1[i]) + ";\n")
f1.write(" func_" + str(100-i) + "();\n")
f1.write("}\n")
f2 = open("creaaaazy.c", "w")
for i in range(100):
f2.write("void func_" + str(100 - (i+1)) + "(){\n")
f2.write(" value ^= " + str(data_1[100-(i+1)]) + ";\n")
f2.write(" func_" + str(100 - i) + "();\n")
f2.write("}\n")
后记
老实说,虽然我在大一因为有着信息学竞赛的基础,所以对程序和代码的理解会稍微轻松一些,可能对于很多非常常规的题也没有太放在心上
但当我真的成为了出题人,才发现自己因此缺少了一个很重要的能力:对难度的把控
更难受的是,一些更高深的内容,碍于自己实践经验太少,无法完全掌握,故也无法加入题目中,作为经验传授给自己的学弟。
总而言之,自己太菜,缺乏做题与实践,但环境不断在变。我现在需要担心的,不光是战力下滑的自己,更有一群嗷嗷待哺的学弟们。
共勉。
fin.