
想了一下,目前小娜小白裙的形象是不是太单一了
但是又想了一下,我的技术力明显不支持太复杂的衣物
不如就先小白裙吧,顺带加点细节。

emm……或许光用文字的话,各位会看得越来越无聊?
那么,看这边(扫描设备过于潦草警告):

这是计算姬小娜,顾名思义,计算机做的脑子,女孩子的身体,看着似乎更加有亲和力一点,但实际上,当她开口说话的时候你就会明白……她为什么叫小娜了。

emm……挺膈应人的。
所以,为了理解小娜是怎么想的,咱们可能得费点劲。
众所周知,计算机系统是我们与机器交互的一个重要链接点。试着理解计算机系统,了解与小娜沟通的过程,或许对我们理解计算机系统有所帮助呢?
我们看看这段代码:print("hello world")
虽然我们习惯从高级语言的视角,用一些成形的单词和指令执行它,但计算机一开始习惯拆开来看它们每一个字母的ascii码,或者说,把它们拆成好几个唯一的二进制编码。毕竟,就像我们熟悉英文一样,小娜熟悉的是机器语言:
hello world = 01101000 01100001 01101100 01101100 01101111 01110111 01101111 01110010 01101100 01100100
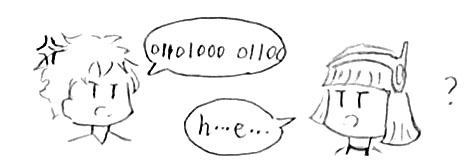
但是我们可不是40k的机油佬,并不能那么轻松地读懂这些仅由01字串组成的东西,更别提表达出来了。所以,对于咱写出来的代码,要让她试着读懂并运行,往往需要一个“翻译官”。
对于和操作系统关系密切的C语言来说,这个“翻译”的过程更有点像……“我翻译我自己”,即,用C语言编写的编译器编译自己。整个程序从我们能看懂的东西,变成小娜能看懂的东西,大概要经历四个阶段,这四个阶段都可以通过编译器的不同指令整出来,具体可以参考原书第七章——
我们一般会在程序开头用诸如#include<stdio.h>的语句调用一些头文件,以方便库函数的调用。预处理器(cpp)则会在预处理的时候将它们和你写出的程序本尊一起,排好序,塞进另一个以.i为拓展名的C程序中。
一个编译器会将.i文件“翻译”成由汇编语言组成的.s文件,对于小娜和她的同类而言,汇编语言的普适性比起高级语言高得多,因为经常有数个高级语言的编译器的目标语言都是同一个汇编语言。
但是,汇编语言只是机器语言“翻译”成,或者说,以某种固定方式定义、组织我们普通人类还能勉强认读的样子,想让小娜读懂,还得再花些功夫。
这个阶段会将我们之前得到的.s文件,通过汇编器(as)打包成一个包含代码和数据的.o文件,一个“可重定位目标程序(一说文件,可能是翻译问题)”,本身是程序的机器语言表示,在文件头的部分会标注“REL”。但是,编译出来的除主函数之外的函数都被识别为了”NOTYPE”,即未知类型,通过文本查看器打开的该文件也大概率是一团乱码。也就是说,到这个阶段,也只是做出了翻译的半成品,小娜实际上还是看不懂。

每一个可重定位文件一般都包含以下三个部分:
1、Elf header:Elf文件的信息,通常的文件都包含一个描述文件大致信息的文件头,而在Linux系统中,C程序的编译结果基本为Elf文件。
对Elf文件头而言比较关键的几个部分包括魔数(Elf Magic,确认文件类型,校验该程序是否可执行)、文件类型(32位还是64位,可重定位/可执行还是共享等,相关数据存放于不同的位置)、文件头长度(可以用以确认Section的起始位置)等。
2、Section:分节容纳已经编译好的机器代码(.text),动、静态变量的值(.data),未初始化或初始化0的各类变量(.bss,Better Save Space),只读数据(.rodata)和其它各类信息。
比较关键的是“符号表”:.symtab。存储着若干符号,对应着源程序的文件名(类型显示为FILE),其中的函数名称,被源程序引用的函数名称(类型显示为NOTYPE,因为定义并不在源程序中),初始化和未初始化的变量(类型显示为OBJECT,全局变量未初始化部分显示为COM(common)对象,与bss区别在于仅包含未初始化全局变量)。书中的描述更偏向于将它们分成全局(谁都可以用)和局部(只能自己用)两部分,而全局变量针对模块的方面可以分成“自己引用别人的”和“别人引用自己的”两部分。
ps:其实符号的局部与否可以依靠static属性存在与否来判断
至于模块是啥玩意……其实实质上也是个程序,但是,一个程序可以由多个源文件编译而来,单个模块实质上也是这些源文件中的一个,但是,作为程序的模块,它并不是一个独立的文件,而是在其中发挥作用的不可或缺的组分(除非你用不上它)。
3、Section header table:描述Section信息的表,表项数和表项大小在Elf header中体现,可以借此计算出表单大小和整个文件的大小。
这个阶段下,连接器(ld)将.o文件转化为无后缀的“可执行目标文件”,也将程序中存在于C标准库中的函数一并合并到主程序。之所以叫“链接”,是因为程序所包含的函数在编译过程中一般都需要依靠上一阶段产生的符号表,将原程序中引用到的一切信息与符号表中的符号关联起来。
当然,我们直接将可重定位目标文件进行链接是不现实的。因为模块与模块,即构成程序的文件之间可能存在着变量名、关键字的冲突,以及引用的变量或函数未经定义之类的问题。这时候,我们要先进行“符号解析”。
对于局部变量,由于命名的限制条件比较苛刻(满足唯一性),所以这种关联完全可以达成简单的一一对应。
但是全局变量就有点可怕了。前面我们提到了“模块”的概念,但是,如果你在编写多个模块的时候,习惯性地在不同文件使用了数个相同名称的变量,那么,此时压力给到小娜——

小娜麻了。在她的思维里,每个变量具有唯一性。而面对这么多同名同姓的兄贵,她脑子里的编译程序要么会报错,要么就以某种方式选出一个作为标准定义,而把剩下的同名变量全扬了,好让自己的脑子不像刚才那样冒烟。
这时候,为了确保程序的正确运行,不同的链接器会做出不同的措施。以Linux系统为例,编译时,编译器向汇编器输出的所有全局变量对应的符号有强有弱,函数和被初始化者为强,未初始化者则为弱。
而链接处理时,强符号被选择的优先级高于弱符号,同时存在多个强符号是不允许的,但弱符号在链接时便可任选其一。比方说,我们的程序不可能有多个main函数,但可以有多个被重复调用的循环变量i。
所有的系统都有生成静态库的能力,静态库即将相关的目标模块打包成的单独文件。这些被调用模块的库不需要被调用,只会在链接的时候,让自己被目标程序用到的部分被复制到程序中。说白了,就像一个工具箱,哪里要用啥,就从里头取——除了里头的工具数量是无限的,其它没啥差别。但是,古早的编译会将整个工具箱塞到程序里,故让程序变得臃肿。静态库技术则是另起一个工具箱,容纳这些取出的工具,再打包到程序中。
当输入链接指令时,C编译器会顺序读取命令,判断输入文件是目标文件还是静态库文件,然后分置到如下三个集合中:
集合E:存放可重定位目标文件(.o),最后,这个集合中的文件会被合并成可执行文件。
集合U:存放引用了但尚未被定义的符号,当连接器扫描到静态库时,则会查找库中的模块是否有这些未定义符号,若存在则将对应模块存入集合E中,并删除集合U中被找到的符号,将对应模块的其它已定义符号存入集合D。
集合D:存放输入文件中已经被定义的符号
在整个与单个静态库链接的过程中,链接器会持续维护这三个集合保持其特性,直到集合U和D不再发生变化,这时候,链接器就会把用不上的部分,也就是E中不存在的部分扬了。然后再去读取下一个文件,若是碰上静态库就以此类推。
理论上,一个完整的程序在这个过程后,集合U为空。若是U不空的话……那就得好好考虑是不是自己忘记调用什么库了。
不过,静态库链接的方法也有要注意的点。因为连接器从左到右读指令,所以,要是输入顺序一错,在调用目标文件之前就调用了库,库会因为U里没有东西而不被调用,于是……boom。

如上进行操作之后,我们便能确保处理出的可执行文件中,每一个调用都和一个既定符号一一对应。我们便可以正式开始链接过程——
汇编器生成目标模块时,并不知道它所引用的外部定义(也就是本体内部不存在)的函数以及全局变量到底在哪,于是,对这些找不到家的孩子,咱就设立一个“重定位条目”,帮助它们在目标文件合成为可执行文件的时候找到自己的归属,即修改这些引用到正确的位置上。
elf文件的重定位条目分为offset(需要被修改的引用的节相对于函数起始位置的偏移)、symbol(被修改引用应该指向的符号)、type(告诉链接器如何修改新的引用,分为相对地址和绝对地址的重定位)和addend(一些类型重要的重定位需要依靠它对被修改引用做偏移调整)四个字段。
代码的重定位条目存放在.rel.text节中,而已初始化数据则放在.rel.data节中。
将所有文件的同类型节(section)合并为一个新节,使得同一程序中所有函数和变量都有指定的运行地址,同时将不同模块的引用通过重定位条目重新定位至一定的位置。
对一个引用而言,其基本从汇编指令call(0xe8)开始,但对于链接前不知道究竟是哪个模块定义了其引用的函数/变量的前提下,重定位条目往往安插于此,而被call的部分则由0填充。
在重定位的过程中,对于函数,首先计算出引用的运行时地址ref_addr = 引用所在函数本身的地址 + offset,而对于全局变量,ref_addr = 引用所在全局变量本身的地址;再通过symbol定义其运行时指向的函数地址ref_ptr = symbol指向的函数的地址 - ref_addr + addend。这样,我们便会得到一个新的call,指向原先的引用指向的目标函数的地址 ref_ptr。
可能这样说难以理解,换个说法,一群工人原本被派来修一条名叫和兴路的笔直道路,但工人们一开始并不知道这条路修到哪里,更别提修多长了,所以只敢在开始修路的地方搭上路标和路障。后来,工程师带着蓝图和地图来了,告诉他们这条路该修到哪,还对着起点和终点比划了一通,丈量出了路的长度。那大家伙自然是开开心心地拿着压路机创过去:
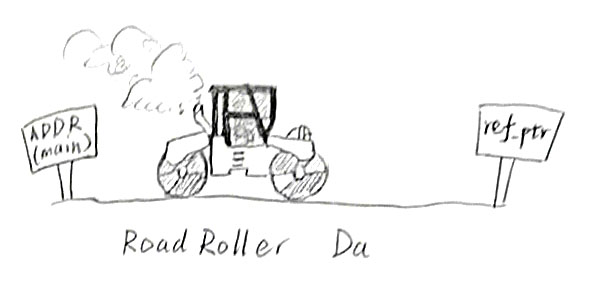
所以,我们得到了已重定位的.text节和.data节,在加载器加载的时候,这些内容会被直接复制到内存,并直接执行。
当然,引用本身分为相对引用(目标为相对于某一地址的偏移,书中介绍了PC相对引用)和绝对引用(目标为在整个程序中的偏移),函数的引用过程使用相对引用,而绝对引用用于全局变量。
终于,经过如上过程,我们得到了一个可执行文件。同可重定位文件结构相仿,这个文件包括了:
1、Elf header:内容与之前相仿,但其中一项记录了程序的入口(所要执行的第一条指令的位置)
2、Segment header table:将连续的文件节映射到运行时的内存段
3、Section:可执行文件的节,其中.init节定义了一个名为”_init”的函数,用于程序的初始化,其它节除了关键的数据节和符号节被重定位完成之外,与原先差别不大,只是因为重定位完成,便不再需要,也不再存在.rel.text节和.rel.data节。
程序运行时,从Elf header到.rodata的代码段,以及.data、.bss数据段在程序运行时会被加载到内存中,其余部分(调试信息等)则不被加载。
4、Section header table:描述Section信息的表。
除此之外,可执行文件的程序头部表(program header table)还描述了可执行文件的连续的片被映射到的连续的内存段,其结构如下:
off:该段代码在文件中的偏移量
vaddr/paddr:该段代码在内存中的起始位置
filesz:代码段在文件中的大小
memsz:代码段在实际运行过程中的大小,会因为加载初值为0的bss段等因素与filesz产生大小的差别
flags:格式为
rwx,对应该片代码是否具有读/写/执行的权限,若某一位为-则为否align:对齐要求,应使vaddr mod align = off mod align,限制段的规模,使得程序到内存的传输更高效,属于优化手段
所以,现在程序的样子,小娜终于能看懂啦~

至于小娜是如何让程序在脑子里运转的……前面的区域,下次再来探索吧(笑)
如果你觉得编者所编写的内容对你理解《深入理解计算机系统》没有帮助,那么请对着编者A接Q接E接长达七页的欧拉,编者是练过的,扛得住(
如果确实有那么一点点的帮助,或者觉得小娜可爱,那么请点个赞支持一波(
这是作者配图的原稿:

坐!大!牢!
然而,真的是纯纯坐大牢吗?
还是我在某些方面犯蠢了呢?
似乎是挺简单的一道汇编题,但是……?
题目在许多渠道都无法正确反汇编甚至运行,比方说ida,die,甚至gdb都救不了,这里就不一一列举失败画面了。无奈只能字节码转汇编硬刚:

注意到loc_68的代码有些眼熟,又是左移4位又是右移5位,又有准确的delta和key,形似tea(tea加密相关可以看看人在码途的文章,应该是处理原文的主要部分。还有这一段:
cmp edx, 23h ; '#'
jl short loc_52
应该对应着tea的加密轮数,tea似乎稳了。但是,这只是我犯浑的开始——
一开始读汇编代码的时候,我注意到被位运算的两个寄存器不一样,寄存器eax和ecx似乎是分存被处理数据的左半和右半。于是在一阵分析后认为这是对原先的tea进行修改,把加密方程变成了这样:
v0 += ((v1<<4) + KEY[0]) ^ (v1 + sum) ^ ((v0>>5) + KEY[1]);
v1 += ((v0<<4) + KEY[2]) ^ (v0 + sum) ^ ((v1>>5) + KEY[3]);
但是我很显然忽略了一个问题,汇编语段里出现了一个ebp寄存器,这玩意的作用相当于开了一个栈,且ebp始终作为某一时刻这个栈的记录存在。在第一个方程过后出现了这样一个语句:
add ebp, ecx
mov ecx, ebp
此时ecx作为左半边的处理结果入栈。而在之后又出现了一个诡异的场景:
mov eax, ebp
shl eax, 4
add eax, 45h ; 'E'
xor ecx, eax
mov eax, ebp
ebp的值同样在之后被用在了eax身上!结合上面的汇编代码,我们不难发现,eax只是被当作临时存储上一级运算结果的变量,真正存储每一次式子运算结果的,一直是ecx!而这也就说明……出题人根本没动过tea,动的是实现tea的方式……
好了,既然认准了是原装的tea,那么直接搬脚本也是合情合理,问题来了,数据呢?要处理的数据呢?
这就要提到我第二次麻瓜的地方了……就是这里。
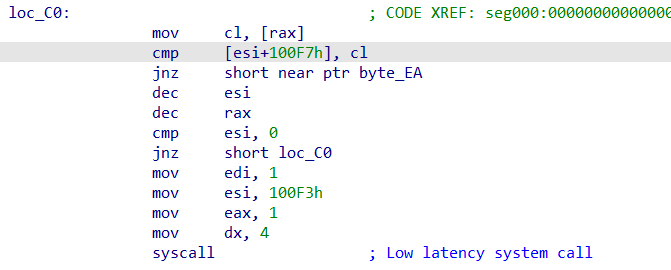
按说到了syscall这块,整个程序也就差不多结束了。但很显然,年轻的我并没有发现什么不对,因为当时那底下还有几个函数——

但是,字节码转汇编程序,某种意义上就是对凌乱数据的解读。而我在一堆函数里迟迟找不到原文或者密文的原因只有可能是一个——
在找主函数的时候,我可能把原本作为数据的部分也转化了。
果然,在跟着题解回滚之后,看到原本在那下面的地方果然是出题人藏都不打算藏的数据集:

那么,该做啥也很清楚了。以下代码参考了0x000000AC和Arr3stY0u:
#include <stdio.h>
#include <stdint.h>
uint32_t KEY[4]={1,0x23,0x45,0x67}; // Key space for bit shifts
int n;
void encrypt(uint32_t* v) {
uint32_t v0=v[0], v1=v[1], sum=0, i; // set up
uint32_t delta=0x67452301; // a key schedule constant, but different in this topic
for (i=0; i < 35; i++) { // basic cycle start
sum += delta;
v0 += ((v1<<4) + KEY[0]) ^ (v1 + sum) ^ ((v1>>5) + KEY[1]);
v1 += ((v0<<4) + KEY[2]) ^ (v0 + sum) ^ ((v0>>5) + KEY[3]);
} // end cycle
v[0]=v0; v[1]=v1;
}
void decrypt (uint32_t* v) {
uint32_t v0=v[0], v1=v[1], sum=0x67452301*35, i; // set up, the sum is different because delta
uint32_t delta=0x67452301; // a key schedule constant
for (i=0; i<35; i++) { // basic cycle start
v1 -= ((v0<<4) + KEY[2]) ^ (v0 + sum) ^ ((v0>>5) + KEY[3]);
v0 -= ((v1<<4) + KEY[0]) ^ (v1 + sum) ^ ((v1>>5) + KEY[1]);
sum -= delta;
} // end cycle
v[0]=v0; v[1]=v1;
}
void dumpdata(uint32_t* v)
{
for (int i=0;i<n;i++)
for (int j=0;j<sizeof(uint32_t)/sizeof(uint8_t);j++)
printf("%c",(v[i] >> (j*8)) & 0xFF);
printf("\n");
return;
}
int main()
{
uint32_t v[] = { 0xde087143,0xc4f91bd2,0xdaf6dadc,0x6d9ed54c,0x75eb4ee7,0x5d1ddc04,0x511b0fd9,0x51dc88fb };
n = sizeof(v)/sizeof(uint32_t);
printf(" Original Values: [");
for(int i=0;i<n;i++)
printf(" %X", v[i]);
printf(" ]");
// for(int i=0;i<n/2;i++)
// encrypt(&v[i*2]);
//
// printf("\n Encrypted: [");
// for(int i=0;i<n;i++)
// printf(" %X", v[i]);
// printf(" ]");
// dumpdata(v); //there's no need encrypt xd
for(int i=0;i<n/2;i++)
decrypt(&v[i*2]); //expand the operation to loop for more data
printf("\n Decrypted: [");
for(int i=0;i<n;i++)
printf(" %X", v[i]);
printf(" ]\n");
dumpdata(v); //to print out data in string format
return 0;
}
flag{327a6c4304ad5938eaf0efb6cc3e53dc}
麻了,汇编一点不会,练底力去。
不知道为什么,我看到了我希腊神话书上前人留下的痕迹。

还在草稿阶段,还只画一半,血压高了然后我直接进行了一波重构:

虽然本人人体画渣,但是……勉强能看吧,希望以后的我不要打死自己
以及,有人说这只狐娘像涂山酱,不知道为什么
我是真的会谢,明明vsCTF的知名度还算可以吧,结果国内搜索引擎基本没有Wp,外网一翻,全是Cry和Web的题解,Re的题解基本都是针对在线题,静态题题解寥寥无几。
麻了,虽然菜,自己动手丰衣足食,就算煮出来的效果堪比雷电将军特殊料理,也好过没东西吃。
焯,又是结构一毛一样巨量文件(我为甚么要说又)

但是好像就是一套单纯的输入数据->加密->判断的机制,并不是地图题(上次复现那套多文件地图题给我整出emotional damage了)。最终,每组数据的结果是一个加密过的串,存储在相对文件头偏移4020的位置:

好嘛,虽然不知道怎么加密的,但是我知道,肯定得先把从file_ 0到file_ 1336这一堆东西导出来:
s = []
for i in range(1337):
with open(f'file_{i}', 'rb') as f:
l = f.read()
s.append(l[0x4020:0x4020+39].decode())
f.close()
fw = open('pickedata.txt', 'w')
for i in range(1337):
fw.write(str(s[i]))
fw.close()
结果就是导出来的这一大串东西具有强烈的base64既视感……
NzPxDxwEv9TLmgFVNjCRjcEJgKMiCJBBvcY0mKoVM0wbgGMlNuvZCXZARwgIGFtIV+……
但是你先别急,虽然能确定完整的加密其中一步应该是base64,但还是先看看这玩意的加密到底是怎么回事。考虑到逆向后的代码有极强的不可读性,我们尝试动态调试。
判定用的串长度为39,我们索性构造一个39长,辨识度还高的串进去测试,比方说abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLM,然后再把断点下在判定过后的任意位置,于是从rdi寄存器得到变换后的结果:

再与原串进行比对:
abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLM
FpGhHqIdJrKiLsMbtjuevkwaxlyfzmAcBnCgDoE
不难发现本体并没有进行base64的操作,而是进行了一个次序的变换。顺着这个思路,我们把原数据每39位进行如上规律的移位。考虑到python的list变量天然分割了这些数据,我们只需要在提取程序上稍作改造(以下代码部分参考Jarosław Keller的题解):
s = []
for i in range(1337):
with open(f'file_{i}', 'rb') as f:
l = f.read()
s.append(l[0x4020:0x4020+39].decode())
f.close()
l = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLM"
a = "abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLM"
b = "FpGhHqIdJrKiLsMbtjuevkwaxlyfzmAcBnCgDoE"
# 干脆在动态调试结果的基础上机操规律,省人工
d = []
for c in l:
d.append((a.find(c), b.find(c)))
# ----------------------------------
x = b''
for t in s:
w = [''] * 39
for a, b in d:
w[a] = t[b]
x += ''.join(w).encode()
x += b'=='
# --标记部分摘自Jarosław Keller dalao--
fw = open('result.txt', 'w')
fw.write(str(x))
fw.close
然后把搓出来的合成肉扔进赛博厨房烧烤:

最后得到一张pdf,往下多划拉划拉就可以找到这个flag:
vsctf{templated_binaries_are_1337}
所以为什么这帮子老外总想着光看几张破图就能让人明白什么(
看外网的题解,不知道为什么把断点下在0x555555555914那里动调,我们打开程序瞅瞅:

好嘛,经典诈骗链接。
die看不出什么,直接搬进ida瞅一眼:

这下真看不懂了(看我凌乱的注释就知道),还得请密码人出山。不过有没有什么让Re手也轻松做出来的办法呢?
有肯定有,那就是暴力硬破,就是花的时间长了点。那么思路很明显了,暴力脚本+从断点输入数据,直接创碎这玩意。问题是……怎么知道自己创没创对位置呢?正常的判断只会对整个串判定T or F,如果要直接比对寄存器,总不能凭空掏出一个地址吧?!而且每一次动态调试出现的输入函数的地址都不相同,什么5582D32C5360、563611541050的都敢冒出来,我真的会谢。
直到我去查找了一下资料,发现gdb可以直接输入start来读取程序的实际入口地址——
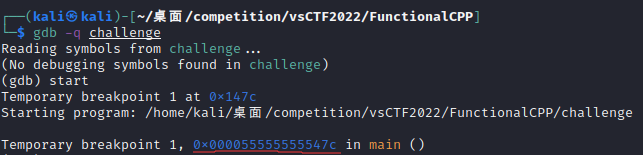
看来很接近了。于是我们看看在主函数的判断语句(忽略我凌乱的注释,那会误导你):


如果我们要通过修改被判断字串的值来爆破,看来是这了。对应判断条件secret位置在主函数偏移约0x497~0x498的位置,刚好是题解里说的玩意——0x555555555914。然后尝试用Python的gdb拓展尝试疯狂爆破。问题来了,用什么爆破呢?我们根据前面的代码可以得知:

输入的是个字符串,至少输出去判断的也是个字符串,所以flag至少是可打印字符集。我们拿不易产生冲突的字符集浅试一手。
下面的代码参考了acdwas和spacewander的架构:
# move.py
# 1. 导入gdb模块来访问gdb提供的python接口
import gdb
# 2. 用户自定义命令需要继承自gdb.Command类
class Move_Py(gdb.Command):
# 3. docstring里面的文本是不是很眼熟?gdb会提取该类的__doc__属性作为对应命令的文档
def __init__(self):
# 4. 在构造函数中注册该命令的名字
super(Move_Py, self).__init__("mv", gdb.COMMAND_USER)
# 5. 在invoke方法中实现该自定义命令具体的功能
# args表示该命令后面所衔接的参数,这里通过string_to_argv转换成数组
def invoke(self, _unicode_args, _from_tty):
strcomb = '0123456789abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ_+?{}' #经典base64字符集
w = 'AAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAAA'
a = 0
# 6. 使用gdb.execute来执行具体的命令
while a < 58:
i = 0
while True:
wline = list(w)
wline[a] = strcomb[i]
gdb.execute(f"r <<< {''.join(wline)}") #直接运行程序,同时把我们要输入的串塞进去
for j in range(a):
gdb.execute('c') #原代码这个判断的断点是个循环,绕过断点继续运行,像极了你疯狂按enter急急国王的样子
if int(gdb.parse_and_eval("$rbx")) == int(gdb.parse_and_eval("$rax")): #当场比较寄存器看看前缀是否相同
w = ''.join(wline)
print(w)
a += 1
break #行的话加入flag豪华午餐
i += 1
# 7. 向gdb会话注册该自定义命令
Move_Py()
于是乎,在把电脑干冒烟之后,你会得到一个flag:
vsctf{1_b37_y0u_w1LL_n3v3r_u53_Func710n4L_C++_1n_ur_L1F3?}
这些鬼题都太折磨了,感觉不是我能好好做的
于是去找题解怼了一波,希望碰到类似的玩意至少能有点头绪
游戏题,打开,发现是经典21点游戏,但是不知道获胜条件。
考虑到游戏随机性过大,强行写算法贪过去不太现实,于是打算逆进去看看获胜条件。ida对付微软的鬼东西基本没辙,于是用一个好用的工具——dnspy解决:
dnSpy is a debugger and .NET assembly editor. You can use it to edit and debug assemblies even if you don’t have any source code available.
——dnSpy official Github site
总而言之,面向对象,可实例化,以及各种优势,你可以找到一万个用它的理由。
我们直接把这玩意和附属dll之类的甩进dnspy,就直接逆出来一堆东西,比方说游戏内置的金手指(作弊码)goldFunc,作弊码分四段,第一段没大用,其余的每次输入正确就会触发对应AchivePoint。
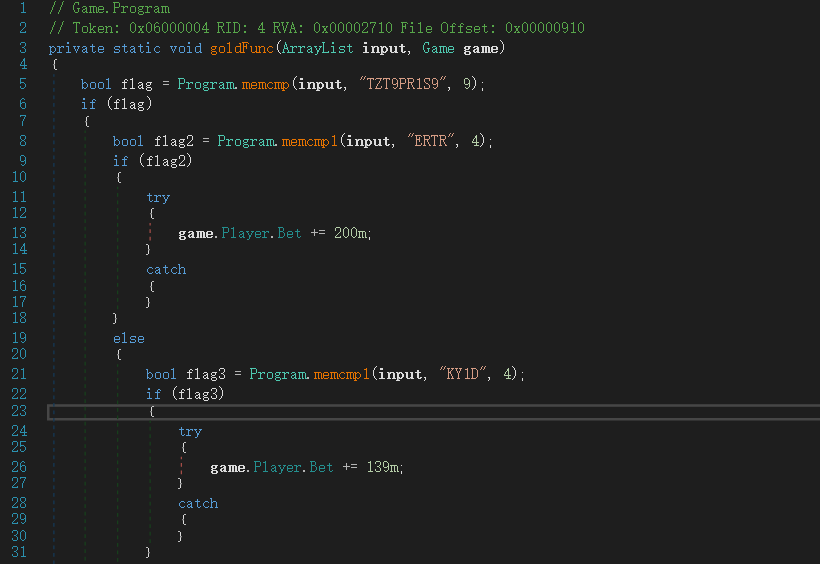
但是先不急,打开Main函数,一开始读gamemassage,并存入全局变量memory。

注意到键盘操作底下塞了个verifyCode:
……
case (ConsoleKey)63:
case (ConsoleKey)64:
continue;
case ConsoleKey.Escape:
Program.verifyCode(arrayList, game);
continue;
case ConsoleKey.Spacebar:
……
点进去,这玩意是调用goldFunc对键盘操作进行判断的,
private static void verifyCode(ArrayList arrayList, Game game)
{
string str = "";
for (int i = 0; i < arrayList.Count; i++)
{
str += arrayList[i].ToString()[0].ToString();
}
Program.goldFunc(arrayList, game);
arrayList.Clear();
}
那么回到作弊码函数,注意到第二段作弊码中AchivePoint处含有如下数据和解码:
byte[] key = new byte[]{ 66, 114,
97,
105,
110,
115,
116,
111,
114,
109,
105,
110,
103,
33,
33,
33
};
ICryptoTransform cryptoTransform = new RijndaelManaged
{
Key = key,
Mode = CipherMode.ECB,
Padding = PaddingMode.Zeros
}.CreateDecryptor();
Program.m = cryptoTransform.TransformFinalBlock(Program.memory, 0, Program.memory.Length);
而在第一段和第三段当中也有对数据进行类似操作:
game.Player.Bet -= 22m;
for (int i = 0; i < Program.memory.Length; i++)
{
byte[] array = Program.memory;
int num = i;
array[num] ^= 34;
}
……
game.Player.Balance -= 27m;
Environment.SetEnvironmentVariable("AchivePoint3", game.Player.Balance.ToString());
BinaryFormatter binaryFormatter = new BinaryFormatter();
MemoryStream serializationStream = new MemoryStream(Program.m);
binaryFormatter.Deserialize(serializationStream);
那么金手指干了些啥不言而喻:
1、对gamemassage进行一个34的异或
2、再进行ECB解码
3、反序列化
那么现在就有两种思路:
1、复现金手指的算法,然后拿到处理过的gamemassage
2、打入金手指,拿到处理过的gamemassage
考虑到做法2临场尝试屡次碰壁,这里就参考Jamie743 dalao的文章,从题目给的原程序扒代码下来对着数据的pg狠狠地铎:
using System.Runtime.Serialization.Formatters.Binary;
using System.Security.Cryptography;
using System.IO;
using System;
Console.WriteLine("Hello, World!");
byte[] memory;
byte[] m;
byte[] key =
{
66,114,97,105,110,115,116,111,114,109,105,110,103,33,33,33
};
ICryptoTransform cryptoTransform = new RijndaelManaged
{
Key = key,
Mode = CipherMode.ECB,
Padding = PaddingMode.Zeros
}.CreateDecryptor();
FileStream fileStream = File.OpenRead("gamemessage");
int num = (int)fileStream.Length;
memory = new byte[num];
fileStream.Position = 0L;
fileStream.Read(memory, 0, num);
m = new byte[num];
for (int i = 0; i < memory.Length; i++)
m[i] = (byte)(memory[i] ^ 34);
m = cryptoTransform.TransformFinalBlock(m, 0, m.Length);
BinaryFormatter binaryFormatter = new BinaryFormatter();
MemoryStream serializationStream = new MemoryStream(m);
binaryFormatter.Deserialize(serializationStream);
FileStream fileStream2 = File.Create("gamemessage2");
fileStream2.Write(m, 0, m.Length);
有一点玄学的地方,这玩意在C#项目中的默认文件输入输出位置不是在当前文件夹,而是bin下的Dbg文件夹,不知道是什么原理。
但是有一点可以肯定,解出来的gamemassage2肯定不能拿编辑器直接看。万策尽,但只是RE方面。微软弄出来的东西跟PE文件经常沾上,关键就是DOS头,也就是所谓的MZ头。我们就010editor打开,找MZ头:

文件头到手,把前面的部分删去省得逆的时候出错。再塞回dnSpy开始逆:

提flag的部分就在这了。首先将num1、num2、num3存入array之后加密,结果存入array2。结合上面的输入,理论上这些数据要通过游戏本体的金手指得到,但由于其过程太过复杂,我们还是利用z3和原gamemassage的Check1函数解方程算了……
找Jamie743 dalao和凡_tastic dalao现学了一波z3位运算操作:
import z3
first = [101, 5, 80, 213, 163, 26, 59, 38, 19, 6, 173, 189, 198, 166, 140, 183, 42, 247, 223, 24, 106, 20, 145, 37, 24, 7, 22, 191, 110, 179, 227, 5, 62, 9, 13, 17, 65, 22, 37, 5]
x = z3.BitVec("num1", 64) #这里是64位程序,保险起见用64位解
y = z3.BitVec("num2", 64)
z = z3.BitVec("num3", 64)
KeyStream = [0] * len(first)
num = -1
for i in range(320): #还是那句话,源码里有现成的就趁热
x = (((x >> 29 ^ x >> 28 ^ x >> 25 ^ x >> 23) & 1) | x << 1)
y = (((y >> 30 ^ y >> 27) & 1) | y << 1)
z = (((z >> 31 ^ z >> 30 ^ z >> 29 ^ z >> 28 ^ z >> 26 ^ z >> 24) & 1) | z << 1)
if i % 8 == 0:
num += 1
KeyStream[num] = ((KeyStream[num] << 1) | (
((z >> 32 & 1 & (x >> 30 & 1)) ^ (((z >> 32 & 1) ^ 1) & (y >> 31 & 1)))))
solver = z3.Solver()
for i in range(len(first)):
solver.add(first[i] == KeyStream[i])
if solver.check() == z3.sat:
mod = solver.model()
print(mod)
于是可以得到三个num:
[num2 = 868387187, num3 = 3131229747, num1 = 156324965]
刚才看解密的主逻辑,还有俩步骤,一个是ParseKey函数:
for (int i = 0; i < 3; i++)
{
for (int j = 0; j < 4; j++)
{
Key[i * 4 + j] = (byte)(L[i] >> j * 8 & 255UL);
}
}
一个是最后一步:
for (int i = 0; i < array5.Length; i++)
{
array5[i] ^= array4[i % array4.Length];
}
通通在py里头复现一波完事:
v = [156324965, 868387187, 3131229747]
array4 = [0]*12
for i in range(3):
for j in range(4):
array4[i*4+j] = (v[i] >> j * 8 & 255)
array5 = [60, 100, 36, 86, 51, 251, 167, 108, 116, 245, 207, 223, 40, 103, 34, 62, 22, 251, 227]
print("flag{", end='')
for i in range(len(array5)):
array5[i] ^= array4[i % len(array4)]
print(chr(array5[i]), end='')
print("}")
flag{Y0u_@re_G3meM3s7er!}
打开,die,发现是go,idagolanghelper,一套行云流水的操作。
找到关键函数main_main、main_Myencode和main_checkflag。在checkflag找到判定正确的字样:

所以这玩意大概率就是检查flag正确性的。主要还得看Myencode,我们能在里面找到密钥main_enc_key_str。

所以接下来,要么确认它是什么加密,要么直接动调弄出密文。密文猜测为被当作checkflag判断条件的qword_55EA78,我们直接下断点(跟涅普的golang题一样下在判断处),掏出kali就是一个林克死大头。

结果密文不是这玩意,反倒是下面的main_enc指向的unk_54DF80。我们直接从里头掏数据出来。Myencode里头不是用了rc4加密的函数吗,我们照解:

真解出来一玩意。再结合之前再checkflag里看到的东西,我们直接弄出flag:
flag{9e1963bbbb1285b993c862a5a6f12604}
只能说调教了半天的bruteHASH,最后竟然治不了这区区sha256碰撞,还是直接自个写了个针对性脚本才好使。
import hashlib
sha256 = "d6332bef2902cd05d5f39a2ed281b8b2247bf5978544a0d5cab08d6bc8fd3ce4"
strr="ABCDEFGHIJKMLNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789"
for i in strr:
for j in strr:
for k in strr:
for l in strr:
asc = i+j+k+l
proof = asc + "MiXq73WVMvdx3jYL"
digest = hashlib.sha256(proof.encode('utf-8')).hexdigest()
if digest == sha256:
finale = proof + '\n' + digest+ '\n'
print(finale)
一开始会给你链接,nc一下,sha256碰撞,你会得到一串巨长无比的base64,想来就是题目的真身了。

直接蔡博厨房烤一烤,上ida,草,走,忽略ጿ ኈ ቼ ዽ ጿ

可以看到程序里这帮子函数基本都一个样。在运行了一阵过后发现这就是一个超大号迷宫,迷宫上每一个节点都连接着十个节点,要我们找到一条路杀出去,满足路长等于1000。
但是在运行的过程中发现,每次输入0都会使得过程重置,回到开始的节点(这里没截上图,各位可以自行理解)
好办,遍历图,最短路,前面填充0,完事。由于图的条件太过充裕,甚至连正经最短路都不用,建议广搜(其实是点太少边太多容易出环,一般最短路反倒不好整)。
另外,在运行后发现每次提供的地图都有细微差别,并且端口还会有超时关停,所以还是得实时提取实时操作,这玩意要像pwn题那样处理。(我不熟python,按官解写的,flag挂了,有人有头绪吗)
from pwn import *
import hashlib
import sys
strr="ABCDEFGHIJKMLNOPQRSTUVWXYZabcdefghijklmnopqrstuvwxyz0123456789"
r = remote("node4.buuoj.cn",25617)
def de_sha256(): #还是之前那样的sha256
r.recvuntil(b'[+] sha256(XXXX+')
salt = r.recv(16).strip().decode()
r.recvuntil(b') == ')
sha256 = r.recv(64).strip().decode()
for i in strr:
for j in strr:
for k in strr:
for l in strr:
asc = i+j+k+l
proof = asc + salt
digest = hashlib.sha256(proof.encode('utf-8')).hexdigest()
if digest == sha256:
print(asc)
r.sendlineafter(b'[+] Plz Tell Me XXXX :', asc.encode('utf-8'))
return
def get_elf(): #在sha256之后提取程序
r.recvuntil(b'map :\n')
data = r.recvuntil(b'That\'s all\n',drop=True)[:-1]
data = base64.b64decode(data)
fd = open('program','wb')
fd.write(data)
fd.close()
de_sha256()
get_elf()
fd = open("./program","rb")
offset = 0x13C0 #所需数据的起始位置
def get_Map(fd,offset):
#接下来经常出现0xd3,代表每个数据组之间的间距,也就是函数偏移
#同理,0xa,每个待取数据之间的偏移
Map = []
for i in range(1000):
addr = offset
for j in range(10):
fd.seek(addr)
fc = u64(fd.read(4).ljust(8,b'\x00'))
if fc <= 0x33765: #话说明明func_999的地址都到0x34000+了,为啥这里设了这么低的上限
fc = fc//0xd3 + i + 1 #取出与当前点连边的点
else: #对于在上限外的点,应该就是对func_1000的条件进行特判吧,条件不符就属于正常点
fc = fc - 0x100000000
if fc > -0xd3:
fc = i
else:
if addr+fc < 0x134A:
fc = 1000
else:
fc = fc//0xd3
fc = i+1+fc
Map.append(fc)
addr += 0xa
offset += 0xd3
return Map
Map = get_Map(fd,offset)
def bfs(Map):
edge = []
keys = []
for st in range(1000):
for ed in range(10):
if ed == 0:
edge.append([])
edge[st].append(Map[ed + st * 10]) #还得麻烦的将一维数组转换成邻接表
for i in range(1000):
keys.append(i)
point_data = dict(zip(keys,edge)) #然后打包成点和边的集合
q = [(0,'')] #python在变量定义上的好处,啥边一块记了
check_map = {}
result1 = None
while len(q):
f = q[0]
q = q[1:]
if(f[0] == 1000):
result1 = f[1]
break
if f[0] not in check_map:
check_map[f[0]] = 1 #ban掉走过的边防止回环
for i in range(10):
if point_data[f[0]][i] not in check_map:
q.append((point_data[f[0]][i],f[1]+str(i)))
return result1
result = bfs(Map)
print(result)
result = str(result)
times = 999 - len(result)
for i in range(times):
r.sendline(b'0')
for i in range(len(result)):
r.sendline(str(int(result[i])+1).encode('utf-8'))
data = r.recvuntil(b'}',drop=True)[:-1]
fin_fd = open('./result.txt','wb')
fin_fd.write(data)
fin_fd.close()
DASCTF{d46dfb6b-610a-48d5-a1d6-2035aa4af67}(未通过)
首次500人+的个人竞技大混战突入前百,感觉还是不错的。

就是解出来的题还是以misc占大头,难受,一个是自己还是只会传统逆向,碰着花活就挂,一个是对go之类的其它语言还是不甚了解,回头害得研究orz。
以及,有道小分密码因为睡过头没来得及研究,寄
以及,只有前三十名才有可能拿fufu,寄中寄
换成温佬应该已经AK了吧(
注意看leak:
def leak(par, c):
assert len(par) == 5
(p,q,n,e,d) = par
print("Here's something for you.")
print("n =",n)
print("e =",e)
print("c_mod_p =",c % p)
print("c_mod_q =",c % q)
可知我们能得到的数据只有c mod p,c mod q,n和e。由于RSA的运算中明文和密文都是在模n意义下得到,这里可以直接用中国剩余定理进行攻击(毕竟题目描述都很直白了,而p*q=n刚好满足中国剩余定理的过程,就变成了求解模n意义下的同余方程组)。
那么,先通过对n开方和sympy等库的函数猜测出构成n的质因子,通过中国剩余定理解出c关于p和q的同余方程得到密文:
from Crypto.Util.number import *
from Crypto import *
from gmpy2 import *
from sympy import *
n = 19955580242010925349026385826277356862322608500430230515928936214328341334162349408990409245298441768036250429913772953915537485025323789254947881868366911379717813713406996010824562645958646441589124825897348626601466594149743648589703323284919806371555688798726766034226044561171215392728880842964598154362131942585577722616354074267803330013886538511795383890371097812191816934883393255463554256887559394146851379087386846398690114807642170885445050850978579391063585254346364297374019309370189128443081285875218288166996242359495992824824109894071316525623741755423467173894812627595135675814789191820979950786791
p = prevprime(int(sqrt(n))) #通过n开方猜测质因子
q = next_prime(p)
print(p*q==n)
inp = invert(q,p) #相当于只有两个式子
inq = invert(p,q)
a1 = 32087476819370469840242617415402189007173583393431940289526096277088796498999849060235750455260897143027010566292541554247738211165214410052782944239055659645055068913404216441100218886028415095562520911677409842046139862877354601487378542714918065194110094824176055917454013488494374453496445104680546085816
a2 = 59525076096565721328350936302014853798695106815890830036017737946936659488345231377005951566231961079087016626410792549096788255680730275579842963019533111895111371299157077454009624496993522735647049730706272867590368692485377454608513865895352910757518148630781337674813729235453169946609851250274688614922
c = ( ( a1*inp*q ) + ( a2*inq*p ) )%n
print(c)
print(p)
print(q)
然后将得到的c、p、q代入rsa求解得到明文:
from libnum import *
from sympy import *
def exgcd_(a, b):
if b == 0:
return 1, 0
else:
k = a // b
remainder = a % b
x1, y1 = exgcd_(b, remainder)
x, y = y1, x1 - k * y1
return x, y
def ext_euclid(a, b):
if b == 0:
return 1, 0, a
else:
x, y, q = ext_euclid(b, a % b)
# q = gcd(a, b) = gcd(b, a%b)
x, y = y, (x - (a // b) * y)
return x, y, q
def fastpower_(a,b,n):
ans = 1
while n > 0:
if n % 2 ==1:
ans= ans * a % b
a = a * a % b
n = n // 2
return ans % b
p = 141264221379693044160345378758459195879285464451894666001807667429134348549398732060237738374405784248735752195059908618618110595213605790125890251970818437656069617772772793421437649079362238861287098916200835889507111259332056471215428085418047179545017193159169629731673653136069647622114441162534727202891
q = 141264221379693044160345378758459195879285464451894666001807667429134348549398732060237738374405784248735752195059908618618110595213605790125890251970818437656069617772772793421437649079362238861287098916200835889507111259332056471215428085418047179545017193159169629731673653136069647622114441162534727202901
e = 65537
c = 11585753035364453623378164545833713948934121662572481093551492504984285077422719062455876099192809170965528989978916297975142142402092047776685650391890015591851053625214326683661927557815767412532952834312578481775648269348260126890551800182341487341482624921905494384205411870866282984671167687789838745481283560185866063970417999748309023918055613674098243729965218609202078551918246640314724590879724609275497227193516782920583249761139685192331805838597293957173545581106446048233248746840771791319643962479707861560044363232580020690857525268858245122996322707454824806268698526881569554077998480289824923073346
n = 19955580242010925349026385826277356862322608500430230515928936214328341334162349408990409245298441768036250429913772953915537485025323789254947881868366911379717813713406996010824562645958646441589124825897348626601466594149743648589703323284919806371555688798726766034226044561171215392728880842964598154362131942585577722616354074267803330013886538511795383890371097812191816934883393255463554256887559394146851379087386846398690114807642170885445050850978579391063585254346364297374019309370189128443081285875218288166996242359495992824824109894071316525623741755423467173894812627595135675814789191820979950786791
phin = totient(n)
# print(n)
# print(phin)
x= exgcd_(e, phin)[0]
d = x % phin
m = fastpower_(c, n, d)
print(n2s(int(m)))
RSA,但是生成了一组贵物pq:
p=getPrime(1024)
q=next_prime(p+(p>>500))
#Zuni: 听说密码学是小学数学来着?
很寄,所以结合题目描述,要解方程。但是这种方程组不是小学数学,所以出题人该打(
电脑不顺手,直接用手算。

然后得到了一个不用暴力,只需要nxtprime的方法(虽然gmpy的next_prime本质上也是暴力),于是码出来(感谢0HB佬提醒,RSA类题目过程涉及实数运算的记得整除):
from gmpy2 import *
from sympy import *
n = 13776679754786305830793674359562910178503525293501875259698297791987196248336062506951151345232816992904634767521007443634017633687862289928715870204388479258679577315915061740028494078672493226329115247979108035669870651598111762906959057540508657823948600824548819666985698501483261504641066030188603032714383272686110228221709062681957025702835354151145335986966796484545336983392388743498515384930244837403932600464428196236533563039992819408281355416477094656741439388971695931526610641826910750926961557362454734732247864647404836037293509009829775634926600458845832805085222154851310850740227722601054242115507
q = next_prime(int(sqrt(n+(n>>500)))) # 既然r要尽可能小,那假设p既定,q-(sqrt(n+(n>>500))也要尽可能小
p = n//q
print('p is :', p)
print('q is :', q)
当然你也可以用sqrt(n)硬梭(虽然我梭了一万年都没梭出来),总之,能求出p和q就行。然后放进你常用的rsa脚本求解就行了。
NepCTF{never_ignore_basic_math}
osz文件为osu谱面,打开进入编辑器快进看到flag
注意不明显的下划线,以及,这里的flag可以有中文。
只能说,对于misc工具还是孤陋寡闻了。Nep的教程里出现了一堆使用插件,必可活用于下次.jpg

使用stegdetect,输入.\stegdetect.exe -tjopi -s 10.0 少见的bbbbase.jpg指令,得知图片为jphide隐写,遂用Jphs打开。
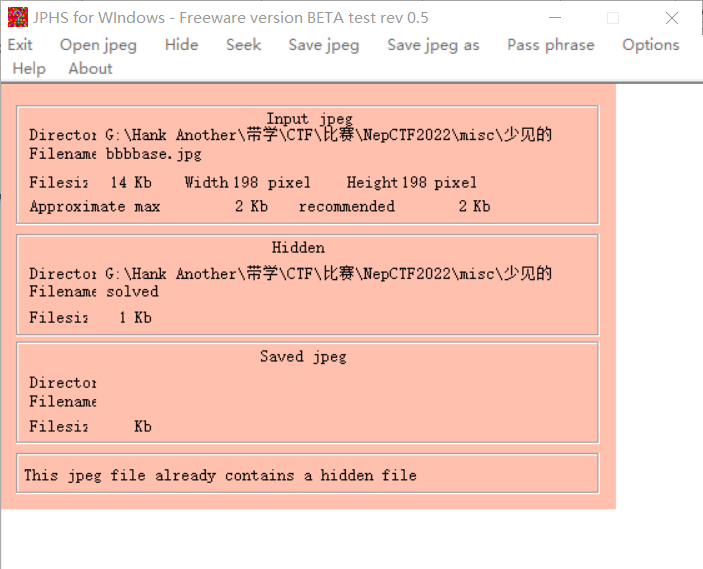
输出无后缀文件,保险起见winhex打开,得到一串编码KkYWdvCQcLYewSUUy5TtQc9AMa。

联想到题目名,排除base64等常见密码的可能,转而去找base61、base58、base92等非常见base,最后使用相对常见的base58得出答案。
NepCTF{Real_qiandao~}
图片大小不对劲,winhex打开,发现其内部藏有大量zip文件。
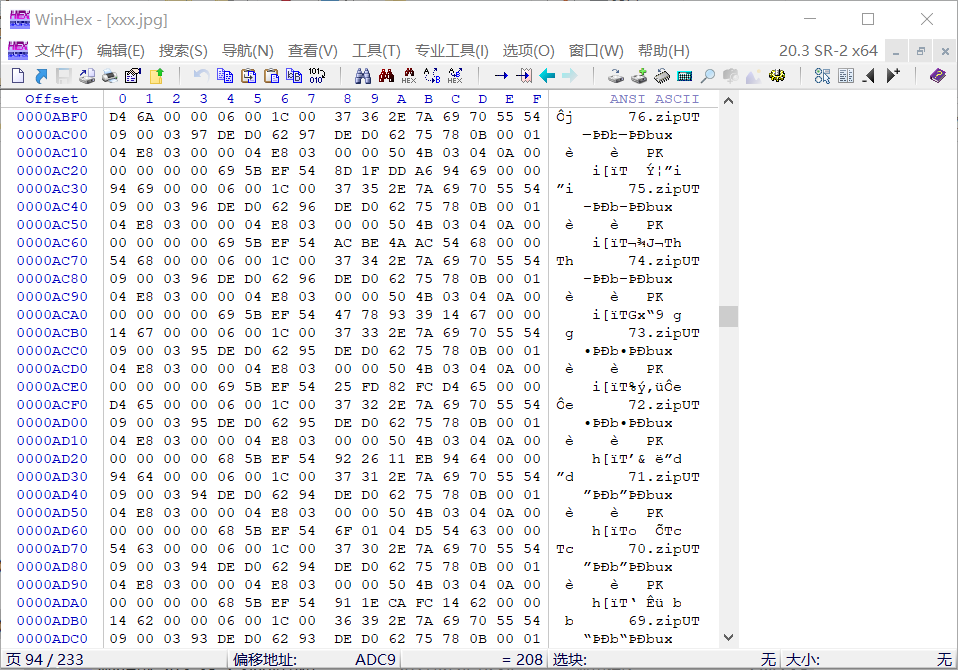
用kali的binwalk拆解后发现入题解所言是套娃,于是直接上脚本拆解:
from zipfile import *
from re import *
zipname = "G:\\Hank Another\\带学\\CTF\\比赛\\NepCTF2022\\misc\\签到题\\_xxx.jpg.extracted\\"+"232.zip"
while True:
if zipname != "G:\\Hank Another\\带学\\CTF\\比赛\\NepCTF2022\\misc\\签到题\\_xxx.jpg.extracted\\1.zip":
ts1 = ZipFile(zipname)
#print ts1.namelist()[0]
res = search('[0-9]*',ts1.namelist()[0])
print (res.group())
passwd = str.encode(res.group())
ts1.extractall("G:\\Hank Another\\带学\\CTF\\比赛\\NepCTF2022\\misc\\签到题\\_xxx.jpg.extracted\\",pwd=passwd)
zipname = "G:\\Hank Another\\带学\\CTF\\比赛\\NepCTF2022\\misc\\签到题\\_xxx.jpg.extracted\\"+ts1.namelist()[0]
else:
print ("find")
拆解到只剩一层时发现压缩包内含流量包,压缩包含加密。winhex再次打开发现文件头并没有加密标记,但目录区有加密标记,为伪加密,直接改掉标记拆包。

打开流量包,发现是键盘usb流量,通过.\tshark.exe -T json -r keyboard.pcap > usbdata.json指令处理后得到操作数据的json文件,但指令无法直接提取操作内容,故手动提取得到usbdata.txt:

然后脚本开跑,得出操作。
from numpy import *
mappings = { 0x04:"a", 0x05:"b", 0x06:"c", 0x07:"d", 0x08:"e", 0x09:"f", 0x0A:"g", 0x0B:"h", 0x0C:"i", 0x0D:"j", 0x0E:"k", 0x0F:"l", 0x10:"m", 0x11:"n",0x12:"o", 0x13:"p", 0x14:"q", 0x15:"r", 0x16:"s", 0x17:"t", 0x18:"u",0x19:"v", 0x1A:"w", 0x1B:"x", 0x1C:"y", 0x1D:"z", 0x1E:"1", 0x1F:"2", 0x20:"3", 0x21:"4", 0x22:"5", 0x23:"6", 0x24:"7", 0x25:"8", 0x26:"9", 0x27:"0", 0x28:"\n", 0x2a:"[DEL]", 0X2B:" ", 0x2C:" ", 0x2D:"-", 0x2E:"=", 0x2F:"[", 0x30:"]", 0x31:"\\", 0x32:"`", 0x33:";", 0x34:"'", 0x36:",", 0x37:"." }
shiftmappings = { 0x04:"A", 0x05:"B", 0x06:"C", 0x07:"D", 0x08:"E", 0x09:"F", 0x0A:"G", 0x0B:"H", 0x0C:"I", 0x0D:"J", 0x0E:"K", 0x0F:"L", 0x10:"M", 0x11:"N",0x12:"O", 0x13:"P", 0x14:"Q", 0x15:"R", 0x16:"S", 0x17:"T", 0x18:"U",0x19:"V", 0x1A:"W", 0x1B:"X", 0x1C:"Y", 0x1D:"Z", 0x1E:"!", 0x1F:"@", 0x20:"#", 0x21:"$", 0x22:"%", 0x23:"^", 0x24:"&", 0x25:"*", 0x26:"(", 0x27:")", 0x28:"\n", 0x2a:"[DEL]", 0X2B:" ", 0x2C:" ", 0x2D:"_", 0x2E:"+", 0x2F:"{", 0x30:"}", 0x31:"|", 0x32:"~", 0x33:":", 0x34:"[double quo]", 0x36:"<", 0x37:">" }
nums = []
shiftag = []
keys = open('usbdata.txt')
for line in keys:
if line[0]!='0' or (line[1]!='0' and line[1]!='2') or line[3]!='0' or line[4]!='0' or line[9]!='0' or line[10]!='0' or line[12]!='0' or line[13]!='0' or line[15]!='0' or line[16]!='0' or line[18]!='0' or line[19]!='0' or line[21]!='0' or line[22]!='0':
continue
nums.append(int(line[6:8],16))
shiftag.append(int(line[0:2],16))
keys.close()
output = ""
for i in range(len(nums)):
if nums[i] == 0:
continue
if nums[i] in mappings:
if shiftag[i]:
output += shiftmappings[nums[i]]
else:
output += mappings[nums[i]]
else:
output += '[unknown]'
print ('output :\n' + output)
偏简单的社工。模拟了一个网友被骗,自己需要靠照片找银行的情况。
通过照片二上“尚德源”的招牌和“琼”字头车牌,确认地区为海南,用google地图进一步确认店铺名称为“尚德源茶园酒店”,以及所在地海南省三亚市天涯区新风街。结合附近地址,如饺子城等店铺确认位置后,找到附近有对应银行为光大银行,银行官网网址即为flag。
die发现repsych.asm,谷歌搜索,发现是一个用于将位图隐藏到ida控制流图的插件。
抬高ida的流图nodes上限,再缩小主函数显示比例,答案出现。
exe文件,用32位ida打开,并未发现明显主函数。发现报错字段:“no goroutines (main called runtime.Goexit) - deadlock!”,确认是go语言,于是用IDAGolangHelper把它的汇编形式变得阳间点。
但是我们怎么确认主函数的位置捏?如果你在汇编里头铁搜索,你八成只能找得到一点残渣:

这时候就得去字节码部分搜,去找数据。这一搜索还真找着了,地址4AF360附近有一个false:

至少找到要用的字符串了,方向多没关系,挨个试一遍,最后发现这个false与off_4D2334关联,而off_4D2334又与sub_499630关联,于是我们终于找到了个类似主函数的东西。
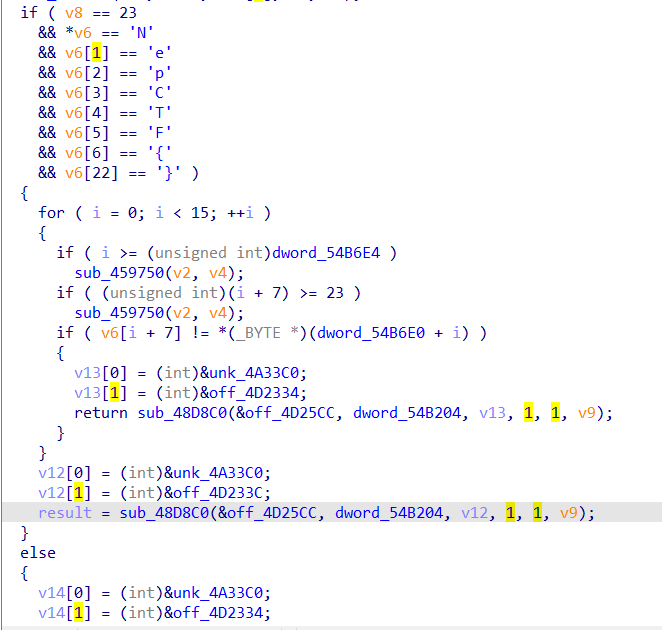
首先判定,长度是否为23,是否符合flag格式,然后是和某个数组进行比对是否一致。但是这个数组在未运行时神龙见首不见尾,我们直接进行动态调试让它现形(随便输一个总长23的flag,在循环判断的地方下断点):

NepCTF{U9et_t0_th3TRUE}
官方题解给出的源码是这样:
#include<bits/stdc++.h>
#include<unistd.h>
using namespace std;
char passage[100000];
int num;
int read_n(int len){
int i=1;
while(i<=len){
scanf("%c",passage+i);
i++;
}
return len;
}
int mask(int x){
return 1<<x;
}
int get_bit(int x){
if(1+x/8>num+1){
printf("too short\n");
exit(0);
}
//printf("%c\n",(passage[1+x/8]));
return !!(passage[1+x/8]&mask(x%8));
}
bool judge_xor(int x,int y){
if(x==y)return 0;
return (get_bit(x)^get_bit(y));
}
bool judge_or(int x,int y){
if(x==y)return 0;
return get_bit(x)||get_bit(y);
}
int main(){
freopen("data.txt","r",stdin);
int len;
cin>>len;
getchar();
num=read_n(len);
if(num!=len)printf("wrong\n");
printf("I will check your input passage\nplease make sure ./data.txt exists and follow the input format\n");
//printf(passage+1);
int n;
scanf("%d\n",&n);
//printf("%d\n",n);
for(int i=1;i<=n;i++){
int op,x,y;
scanf("%d %d %d",&op,&x,&y);
if(op==1){
if(!judge_or(x,y)){
printf("Wrong passage on %d\n",i);
exit(0);
}
}
else{
if(!judge_xor(x,y)){
printf("Wrong passage on %d\n",i);
exit(0);
}
}
}
printf("Great!,But you may check your input if it is passage!\n");
return 0;
}
但在ida里其实这俩长得一毛一样:
_BOOL8 __fastcall sub_C24(int a1)
{
int v1; // ebx
if ( a1 / 8 + 1 > dword_24A16E0 + 1 )
{
puts("too short");
exit(0);
}
v1 = *((char *)&unk_2489040 + a1 / 8 + 1);
return (v1 & (unsigned int)sub_C0D(a1 % 8)) != 0;
}
_BOOL8 __fastcall sub_CEC(unsigned int a1, unsigned int a2)
{
if ( a1 == a2 )
return 0LL;
return sub_C24(a1) || sub_C24(a2);
}
bool __fastcall sub_CAC(int a1, int a2)
{
_BOOL4 v3; // ebx
if ( a1 == a2 )
return 0;
v3 = sub_C24(a1);
return v3 != sub_C24(a2);
}
__int64 __fastcall main(__int64 a1, char **a2, char **a3)
{
unsigned int i; // [rsp+0h] [rbp-10h]
unsigned int v5; // [rsp+8h] [rbp-8h]
unsigned int v6; // [rsp+Ch] [rbp-4h]
sub_7AA(a1, a2, a3);
freopen("passage.txt", "r", stdin);
dword_24A16E0 = read(0, &unk_2489041, (size_t)&off_1869F);
puts("I will check your input passage\nplease make sure ./passage.txt exists.");
freopen("data", "r", stdin);
for ( i = 0; (int)i <= (int)&off_2E06BF; ++i )
{
v5 = dword_3720[3 * i + 1];
v6 = dword_3720[3 * i + 2];
if ( dword_3720[3 * i] == 1 )
{
if ( !sub_CEC(v5, v6) )
{
printf("Wrong passage on %d\n", i);
exit(0);
}
}
else if ( !sub_CAC(v5, v6) )
{
printf("Wrong passage on %d\n", i);
exit(0);
}
}
puts("Great!,But you may check your input if it is passage!");
return 0LL;
}
无非就是在题设中dword_3720给定了操作,基本都是用按字节操作去求某些东西,一道算法题。这里就要扯到一个我曾经打OI时没注意到的一个知识盲区——2-SAT。
可以证明,当k>2时,k-SAT是NP完全的。因此一般讨论的是k=2的情况,即2-SAT问题。
我们通俗的说,就是给你n个变量ai,每个变量能且只能取0/1的值。同时给出若干条件,形式诸如(not)a[i]opt(not)a[j]=0/1,其中opt表示and,or,xor中的一种,而求解2-SAT的解就是求出满足所有限制的一组a。
————摘自hl666的文章
这么说来,我们之前提到过的搜索算法似乎很适合求解这种贵物。题目本身就是一个2-SAT问题,看起来只需要把2-SAT问题转换为一张有向图就行了。但……怎么转换呢?
于是我去翻了各种2-SAT的模板题……这simple个锤子,出题人吃了吗,没吃吃我一拳(
虽然这2-SAT的结构还算简单,就只有或和异或,但这鬼屎数据量简直屎到劲,根本提不出来(从0x3720到0x1869B,IDA直呼太大了进不去)。更不要说这张奇大无比的图它还有环,还有环口牙!!!而且自己测试的时候官解都挂了……离谱。
(后来发现是提数据的时候逼到ida软件本体读取上限了,看来得用其它工具)
缺失模块。
1、请确保node版本大于6.2
2、在博客根目录(注意不是yilia根目录)执行以下命令:
npm i hexo-generator-json-content --save
3、在根目录_config.yml里添加配置:
jsonContent:
meta: false
pages: false
posts:
title: true
date: true
path: true
text: false
raw: false
content: false
slug: false
updated: false
comments: false
link: false
permalink: false
excerpt: false
categories: false
tags: true
